I noticed this information when I looked this flavor up on the other side:
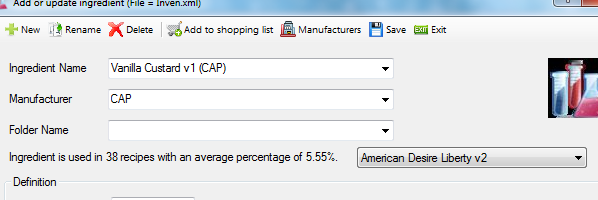
Vanilla Custard v1 - Capella Flavors
You have this flavor
Bottle size: 13.00
ml Cost: 2.50
Weight in grams per ml: 1.0670
Flavor carrier: [ ] PG [ ] VG [x]Other
Preferred single flavor mix: ?.?? %
Flavoring MAY contain diacetyl - a flavoring used to create a butter flavor.
Contains Acetoin and Acetyl Propionyl
Materials Safety Data Sheet (MSDS) document
Manufacturer specified gravity: 1.067 g/ml
Percentages in recipes
Average mixing quantity: 4.3% (Median: 3%)
Minimum used quantity: 0%
Maximum used quantity: 75.8%
Single flavor recommendations: 141
Average quantity: 10.2% (Median: 10.0%)
Minimum used quantity: 0.5%
Maximum used quantity: 30.0%
Information I obtained from ANOTHER SOURCE.:
Vanilla Custard 12,50%
Averaged from: 8% 20% 11%18% 7% 11,00%
On this particular flavor the Average quantity: 10.2% (Median: 10.0%) is not too far off Dampfaromen-Prozentebut’s 12.5% I’m wondering how many statistical outliers are used in ELR’s average?
Sometimes data might look like 6, 4.5
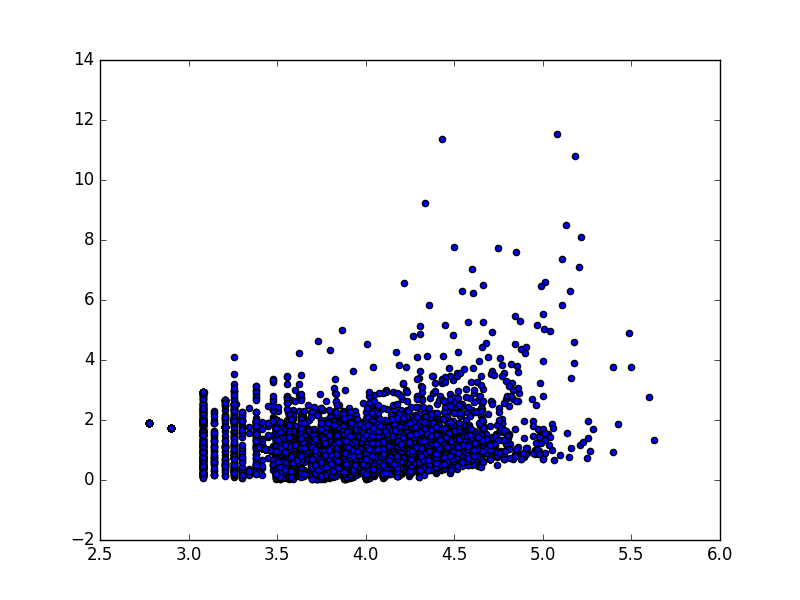
may actually be closer to 1.5, 4 once the outliers are removed.
This may be a good argument to have a check box for dripper/tanker, or possibly a way to view the data and manually deselect outliers hooligans and pranksters.